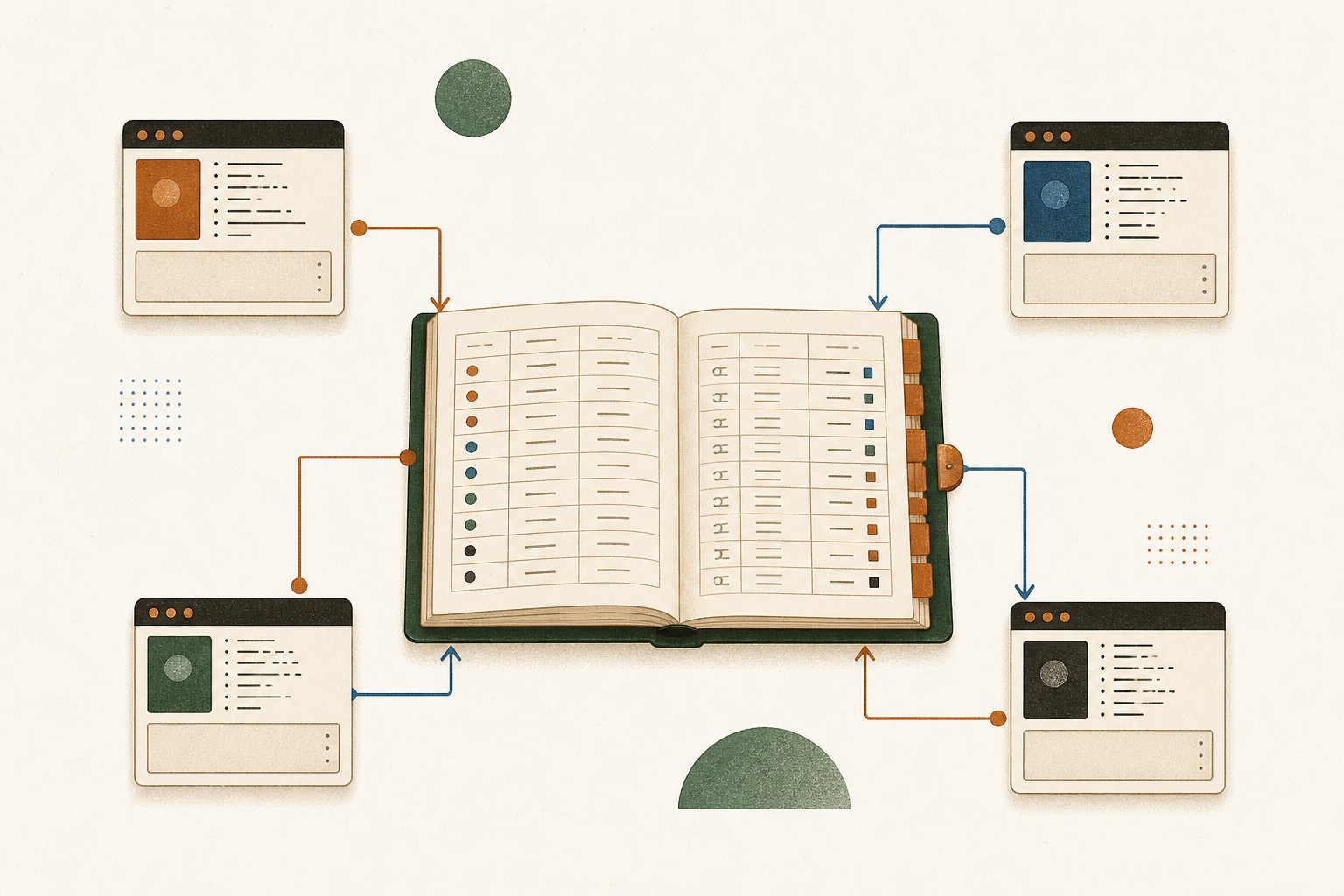
Fix login timeout on /api/session
Status
todo
Priority
P2
Type
bug
Project
api
Actor
human:alice
Created
just now
Description
Sessions are expiring after 5 minutes instead of the configured 24 hours. Reproduces on staging when refresh tokens are issued out of order.
Activity
- just nowhuman:alice created the task
One database. Whatever wrote it, your shell or your agent, appears here.